See these metrics for your own team
CodePulse turns your GitHub history into engineering insights in about 5 minutes. Free to start, no credit card.
Get started freeYour team opens a pull request. Three days later, it's still waiting for review. The developer has moved on to other work. When feedback finally arrives, they've lost context. Sound familiar? Cycle time - the clock from first commit to merge - is where most teams bleed the most time. And unlike hiring or tooling, it's fixable in weeks.
How do you reduce PR cycle time without sacrificing review quality?
The fastest way to reduce PR cycle time is to tackle the waiting phase, which is usually the largest bottleneck. Start by measuring your current breakdown (coding, waiting for review, in review, merge), then set review SLAs with a 4-hour first-response target for PRs under 400 lines. Teams that do this consistently see 30%+ reductions within a month. CodePulse breaks your cycle time into these four phases automatically, so you can see exactly where time goes.
This is the playbook we used to cut cycle time by 47% in 30 days. You'll learn how to find bottlenecks, set up review SLAs, and keep the gains from slipping.

🔥 Our Take
Cycle time is a signal, not a goal. If you're optimizing cycle time at the cost of review quality, you're optimizing the wrong thing.
Fast cycle time with no review is worse than slow cycle time with thorough review. The moment cycle time becomes a target -tracked on dashboards, tied to performance -teams will find ways to hit the number. They'll rubber-stamp approvals, skip meaningful feedback, and merge before they should. You'll get faster PRs and worse software. Cycle time tells you where friction exists. It doesn't tell you whether that friction is waste or valuable diligence.
Why Does PR Cycle Time Matter?
Every hour a pull request sits idle is an hour of lost shipping time. But the real cost runs deeper:
"A PR waiting for review is inventory sitting on a shelf. It depreciates. Conflicts accumulate. Context fades. The longer it sits, the less valuable the merge."
The Hidden Costs of Long Cycle Times
- Context switching: Developers waiting for review start other work. When feedback lands, they need 15-30 minutes just to reload the original context.
- Merge conflicts: The longer a branch lives, the more it drifts from main. Fixing conflicts is pure waste.
- Bigger PRs: Slow reviews push developers to batch changes into larger PRs. Larger PRs get worse reviews. Worse reviews ship more bugs.
- Weaker feedback: A PR that's been open for days creates pressure to just approve it. Reviewers skim instead of read.
The Compounding Effect
If your team opens 20 PRs per week and each one takes 3 extra days to merge, that's 60 developer-days of work-in-progress sitting in queues. At any moment, your team is carrying the cognitive load of dozens of open branches.
Faster cycle time doesn't just speed up PRs. It shrinks the mental load of tracking open branches and tightens the feedback loop for your whole team.
How Do You Measure PR Cycle Time?
You can't fix what you can't see. Here's how to get real cycle time data from GitHub.
What to Measure
Total Cycle Time: Time from PR opened to PR merged. This is your headline metric.
Break it down into components:
- Time to First Review: How long until someone starts reviewing? This is often the largest component.
- Review Duration: Time spent actively in review (from first review to approval)
- Time to Merge After Approval: Delay between approval and actual merge
Establishing Baselines
Calculate your current metrics over the past 30-90 days:
- Average cycle time (mean)
- Median cycle time (often more useful -less skewed by outliers)
- 90th percentile cycle time (your "worst case" scenarios)
- Cycle time by team/repository (to identify specific problem areas)
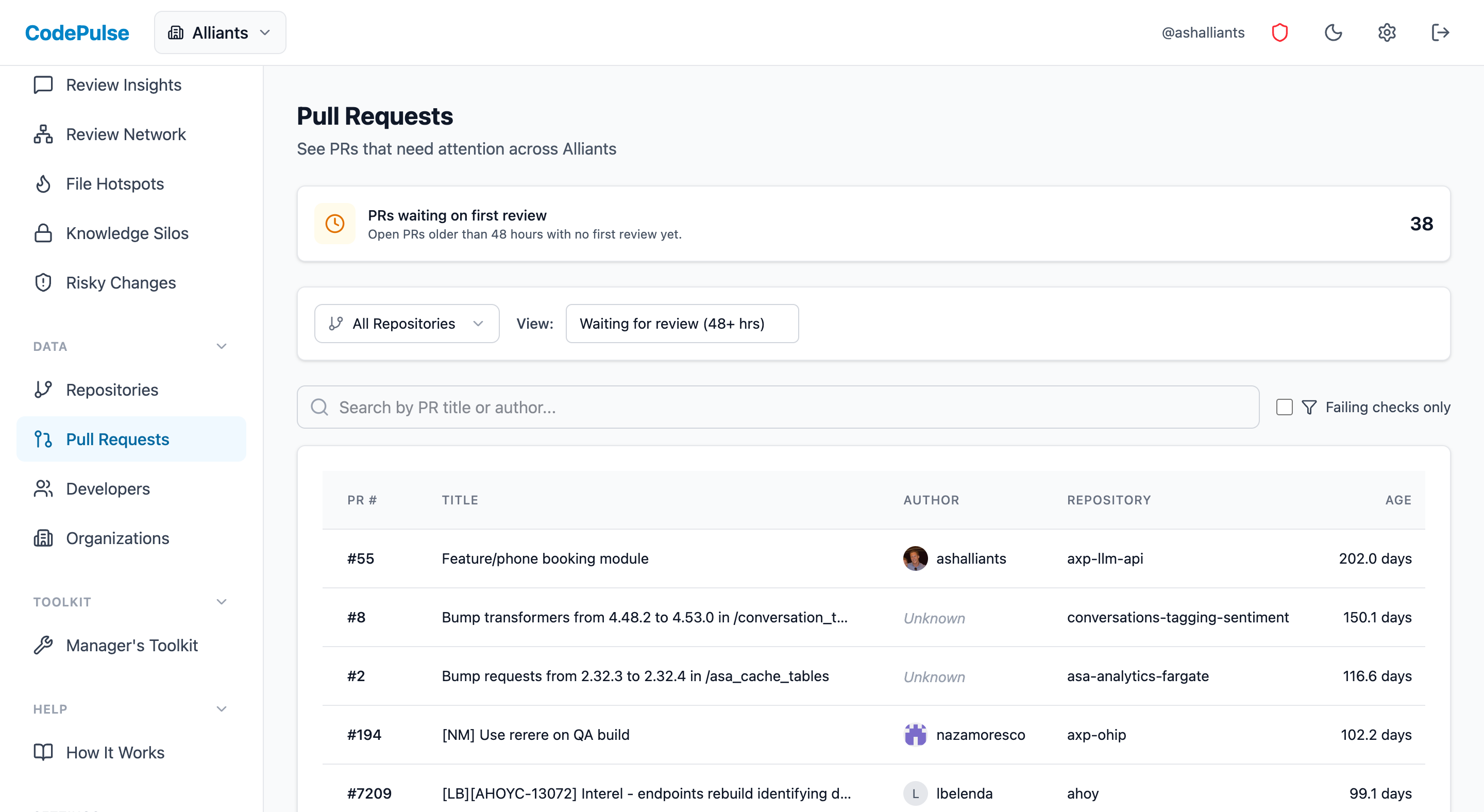
📊 How to See This in CodePulse
Navigate to Dashboard to view your cycle time breakdown:
- The cycle time chart shows your median and trend over time
- Hover over the breakdown to see the 4 components: coding time, wait for review, review duration, and merge time
- Filter by repository to identify which repos have the longest cycle times
- Switch between daily, weekly, and monthly views to spot patterns
Industry Benchmarks
According to the 2024 DORA State of DevOps Report, the gap between top and bottom teams is widening. High performers shrank from 31% to 22%, while low performers grew from 17% to 25%. Lead time is a key separator:
| Performance Level | PR Cycle Time |
|---|---|
| Elite | < 1 day |
| High | 1-3 days |
| Medium | 3-7 days |
| Low | > 7 days |
If your median is above 3 days, there's a lot of room to improve. But here's what matters more: DORA found that teams where people feel safe to take risks and push back on bad deadlines ship faster than teams chasing speed metrics.
What Are the Most Common Cycle Time Bottlenecks?
Long cycle times always have a root cause. Here are the four biggest and how to spot them.
1. Review Queue Bottleneck
Symptom: Long time to first review, especially for certain repositories or teams.
Diagnosis: Check who's doing the reviews. If a few people handle most of the load, that's your bottleneck. Look for:
- Single reviewers handling >20% of team reviews
- Repositories with only 1-2 qualified reviewers
- Senior engineers spending >4 hours/day on reviews
For strategies on distributing review load more evenly, see our Review Load Balancing Guide.
2. Large PR Bottleneck
Symptom: High variance in cycle time. Some PRs merge quickly; others take forever.
Diagnosis: Plot PR size against cycle time. PRs under 400 lines get better reviews - above that, reviewers start skimming. PRs waiting over 24 hours are 2x more likely to be abandoned. Check:
- Average PR size (additions + deletions)
- Percentage of PRs over 400 lines
- Cycle time segmented by PR size
"The best predictor of review quality isn't reviewer seniority -it's PR size. After 400 lines, reviewers stop reading and start skimming."
3. Timezone/Availability Bottleneck
Symptom: PRs opened late in the day take much longer to merge than those opened in the morning.
Diagnosis: Analyze cycle time by PR creation hour. If PRs created after 3pm consistently take 2x longer, your team may lack overlapping working hours for timely reviews. For distributed teams, see our guide on async code review for distributed teams.
4. CI/CD Bottleneck
Symptom: PRs approved but not merged for hours or days.
Diagnosis: Check time from approval to merge. If this is consistently high, look for:
- Slow CI pipelines blocking merge
- Flaky tests requiring reruns
- Manual deployment gates
When Is a Slow PR Cycle Time Actually Fine?
Not every slow PR is a problem. Before you grind cycle time down to zero, know when slower is better:
Legitimate Reasons for Longer Cycle Times
- Complex architectural changes: A PR that redesigns your auth system should take longer than a typo fix. If reviewers are asking hard questions and requesting design changes, that's the review process working.
- Cross-team coordination: Changes affecting multiple teams need input from multiple stakeholders. This isn't a bottleneck -it's appropriate governance.
- Security-sensitive code: Payment processing, authentication, encryption -these deserve extra scrutiny even if it adds days.
- Junior developer growth: A PR where a senior spends 3 hours mentoring a junior through improvements isn't "slow" -it's investment.
- First-time contributors: New team members need more thorough reviews to learn the codebase. Their cycle time will naturally be higher.
"If every PR merges in under 4 hours, you're either a team of clones or you've stopped giving meaningful feedback."
The Tradeoff Matrix
| PR Type | Target Cycle Time | Acceptable Variance |
|---|---|---|
| Bug fixes, typos | < 4 hours | Low -these should be fast |
| Feature additions | 1-2 days | Medium -depends on scope |
| Refactors, tech debt | 2-3 days | Higher -benefits from deliberation |
| Architecture changes | 3-5 days | High -speed here is risky |
| Security-sensitive | 2-5 days | Very high -thoroughness trumps speed |
When reviewing your cycle time metrics, segment by PR type. A 4-day architecture PR and a 4-day typo fix are very different situations.
Questions to Ask Before Optimizing
- Are PRs slow because of waste (waiting) or value (thoughtful review)?
- Would faster merges have prevented any incidents, or caused them?
- Are your best engineers complaining about review delays, or about pressure to approve too quickly?
- When a PR takes longer, does it emerge better?
If the honest answer is that your slow PRs are slow because they're getting better, you may not have a problem worth solving. Focus your optimization efforts on the PRs that are slow due to neglect, not thoroughness.
How Should You Set Up Code Review SLAs?
Review SLAs turn "I'll get to it" into a clear team commitment with real deadlines.
Setting the Right SLA
Recommended starting points:
Code Review SLA Framework: ┌─────────────────────────────────────────────────────────┐ │ PR SIZE │ FIRST RESPONSE │ TOTAL CYCLE TIME │ ├─────────────────────────────────────────────────────────┤ │ Small (<100L) │ 2 hours │ Same day merge │ │ Medium (<400L) │ 4 hours │ 24 hours │ │ Large (>400L) │ 8 hours │ 48 hours (review *) │ └─────────────────────────────────────────────────────────┘ * Large PRs should trigger a conversation about breaking them down, not just longer SLAs. Follow-up Response SLA: 2 hours after author updates ESCALATION PATH: - Yellow: PR at 75% of SLA → Slack reminder to reviewers - Red: PR at 100% of SLA → Escalate to team lead - Critical: PR at 200% of SLA → Auto-tag EM for review
Important: SLAs should be team commitments, not individual mandates.
Implementing SLA Enforcement
Visibility: Put SLA status on a shared dashboard. A simple view of "PRs near SLA" and "PRs past SLA" keeps the team honest.
Alerts: Set up automated alerts when PRs approach or exceed SLA thresholds. Slack notifications work well -send to the team channel, not individuals. See our guide on setting up engineering metric alerts for detailed configuration advice.
Escalation: For PRs well past SLA, have a clear path. The author should feel fine pinging reviewers directly - no awkwardness needed.
Avoiding SLA Anti-Patterns
- Don't punish individuals: If someone consistently misses SLAs, investigate their workload -don't blame them.
- Don't sacrifice quality: An SLA that leads to rubber-stamp approvals defeats the purpose.
- Don't ignore context: Complex PRs may legitimately need more time. SLAs should be guidelines, not absolutes.
What Does a 30-Day Cycle Time Improvement Plan Look Like?
Week 1: Measure and Baseline
- Day 1-2: Set up cycle time tracking. Calculate current averages and identify your biggest repositories/teams.
- Day 3-4: Break down cycle time into components. Identify which phase (waiting for review, in review, waiting to merge) takes longest.
- Day 5: Share findings with team leads. Get buy-in that this is worth improving.
Week 2: Quick Wins
- Day 6-7: Implement review rotation or "review champion" role. Ensure someone is always responsible for reviewing incoming PRs.
- Day 8-9: Set up basic alerts for PRs waiting >4 hours for first review.
- Day 10: Communicate new review SLA expectations to the team. Make it a team commitment, not a top-down mandate.
Week 3: Address Root Causes
- Day 11-14: If large PRs are an issue, establish PR size guidelines and provide training on breaking down work.
- Day 15-17: If review concentration is an issue, begin cross-training to expand your reviewer pool.
- Day 18-21: If CI is slow, prioritize pipeline optimization or add caching.
Week 4: Measure and Iterate
- Day 22-25: Measure new cycle times. Compare to baseline.
- Day 26-28: Identify remaining bottlenecks. Adjust SLAs or processes as needed.
- Day 29-30: Share results with the team. Celebrate improvements. Set targets for the next 30 days.
How Do You Sustain Cycle Time Improvements?
Most teams see gains in the first month, then drift back. Here's how to lock in the progress.
Make Metrics Visible
Put cycle time on a shared dashboard. Bring it up in retros. What the team sees and talks about is what gets better.
Celebrate Progress
When cycle time drops, call it out. "We shipped 40% faster this month" is real fuel. Teams that see results keep pushing.
Regular Review of Outliers
Each week, look at the PRs that took way longer than usual. Dig into why they stalled. The patterns you find will prevent the next stall.
Continuous Improvement Mindset
Once you've hit your 30% reduction, don't stop. The best teams never stop tuning. Set new targets, find new bottlenecks, and keep going. For a deeper dive into the components of cycle time, see our Cycle Time Breakdown Guide.
Protect Against Backsliding
Set up alerts if cycle time trends upward. Catch regressions early before they become the new normal. See our Alert Rules Guide for configuration best practices.
What Should You Remember About Cycle Time?
Cutting cycle time is not about merging every PR faster. It's about removing the waits that don't add value while keeping the reviews that do.
The best teams didn't get fast by chasing speed. They built trust, kept PRs small, automated the grunt work, and made review a shared job instead of one person's burden.
If you take one thing from this guide: use cycle time to understand your process, not to judge your people. The moment it becomes a target, you'll get faster numbers and worse software.
For more context on how to think about engineering metrics holistically, see our DORA Metrics Guide and our guide on measuring team performance without micromanaging.
Frequently Asked Questions
A good PR cycle time depends on PR type and team context. For bug fixes and small changes, aim for same-day merge (under 4 hours). For standard feature PRs under 400 lines, 24 to 48 hours is healthy. Architecture changes and security-sensitive code may legitimately take 3 to 5 days. The median cycle time for high-performing teams is under 24 hours according to DORA research.
See these insights for your team
CodePulse connects to your GitHub and shows you actionable engineering metrics in minutes. No complex setup required.
Free tier available. No credit card required.
See These Features in Action
Break down cycle time into coding, waiting, review, and merge phases.
Interactive graph of review relationships and workload distribution.
Related Guides
DORA Metrics Explained: The 4 Keys Without the Hype
A complete breakdown of the four DORA metrics - deployment frequency, lead time, change failure rate, and MTTR - with honest benchmarks and gaming traps to avoid.
The 4-Minute Diagnosis That Reveals Why Your PRs Are Stuck
Learn to diagnose exactly where your PRs are getting stuck by understanding the 4 components of cycle time and how to improve each one.
Engineering Metrics That Won't Get You Reported to HR
An opinionated guide to implementing engineering metrics that build trust. Includes the Visibility Bias Framework, practical do/don't guidance, and a 30-day action plan.
Your Best Engineer Is About to Quit (Check Review Load)
Learn how to identify overloaded reviewers, distribute review work equitably, and maintain review quality without burning out your senior engineers.
Software Project Planning: Stop Guessing, Start Forecasting
Most project plans fail because they're based on estimates, not data. This guide shows how to plan software projects using git metrics, historical velocity, and probabilistic forecasting.
DevOps Observability: Logs, Metrics, and Traces
Observability goes beyond monitoring to help you understand why systems break, not just when. This guide covers the three pillars (logs, metrics, traces), implementation strategies, and tool comparisons.
Remote Code Reviews Are Broken. Here's the 3-Timezone Fix
How to run effective code reviews across time zones without sacrificing quality or velocity.
3 GitHub Review Features That Cut Our Review Time in Half
Most teams underuse GitHub native review features. Learn CODEOWNERS, branch protection, and suggested changes to speed up reviews without new tools.